Gautham Vasan
I'm a PhD candidate in Computing Science at the University of Alberta, advised by Dr. Rupam Mahmood.
I aim to understand the computational principles underlying intelligence. To this end, I build agents that can continually learn, adapt, and improve throughout their lifetimes.
Previously, I deployed deep reinforcement learning to a fleet of warehouse robots used by Gap at Kindred AI. I’ve also worked on imitation-bootstrapped RL during internships at Sanctuary AI and the University of Freiburg. During my M.Sc, I worked with Dr. Patrick Pilarski to develop learning from demonstration techniques that amputees can use to teach their own prosthetic arms. Long before that, I studied Instrumentation and Control Engineering at NIT Trichy, India.
CV
Google Scholar
GitHub
LinkedIn
Goodreads
Email

Streaming Deep Reinforcement Learning
Streaming learning is about learning from a stream of experience:
• as soon as they arrive
• using the most recent sample
• without storing past experience in raw form.
Our algorithms: Action Value Gradient (AVG) & Stream-X
RLScan: Learning to Scan Apparel Barcodes
An RL policy is trained end-to-end directly in production, learning from a fleet of robots across multiple production sites.
Kindred SORT at Gap Inc | State of AI Report (2021) |
Kindred SORT AI Robots Pick 100 Million Lifetime Units
Reward Design in Reinforcement Learning
Using -1 every timestep until termination as the reward can lead to superior learned behaviors. Here's the paper that explains why.
Learning From Demonstration for Prosthetic Arms
Teaching a Powered Prosthetic Arm with an Intact Arm Using Reinforcement Learning.
M.Sc Outstanding Thesis Award in Computing Science
I write for fun/clarifying ideas for myself. My technical posts can be found below. My personal blog is hosted at enlightenedidiot.net

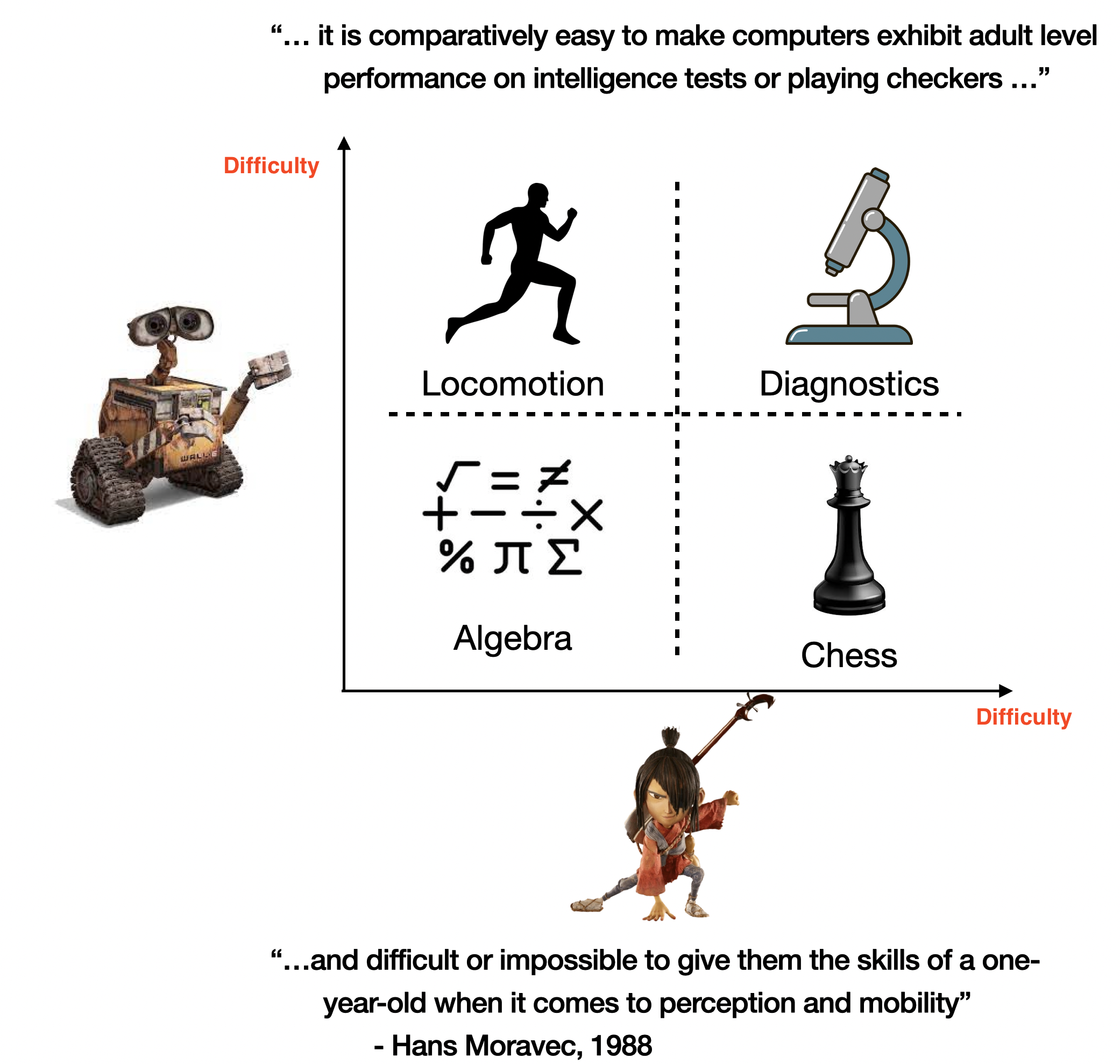


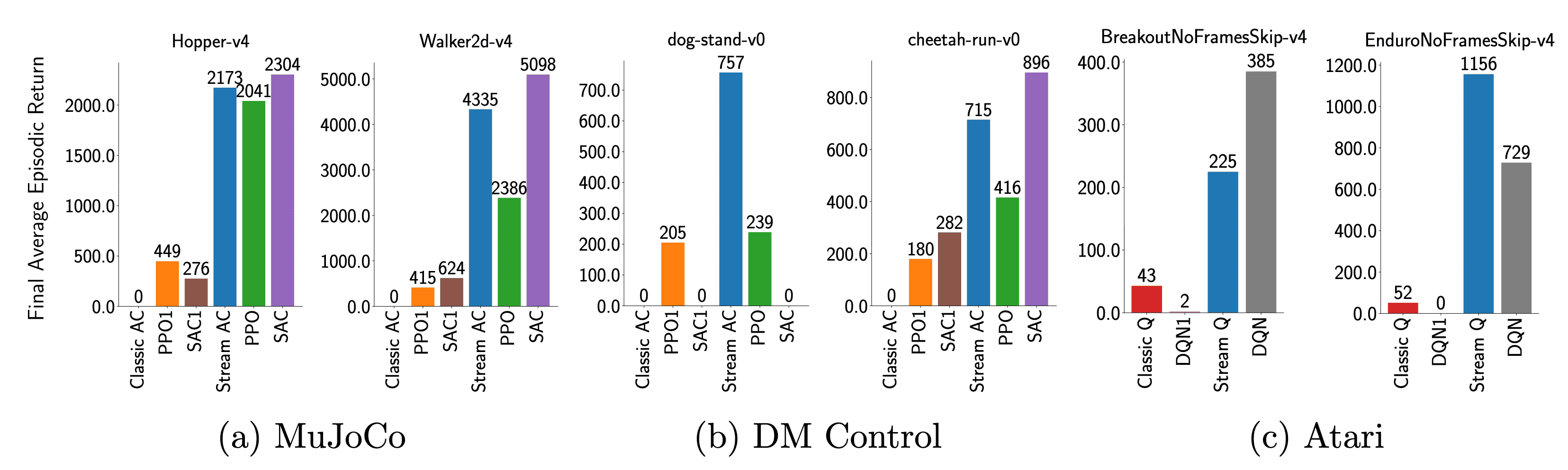
Deep Policy Gradient Methods Without Batch Updates, Target Networks, or Replay Buffers
Gautham Vasan, Mohamed Elsayed, Alireza Azimi, Jiamin He, Fahim Shahriar, Colin Bellinger, Martha White, A. Rupam Mahmood
NeurIPS 2024
Paper •
Code •
Colab •
Video Demo •
Cohere4AI Talk
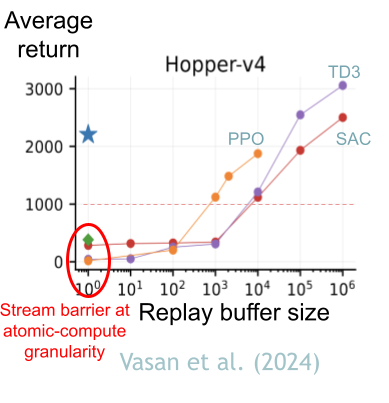
Streaming Deep Reinforcement Learning Finally Works
Mohamed Elsayed, Gautham Vasan, A. Rupam Mahmood
Pre-Print, NeurIPS FitML Workshop 2024
Paper •
Code

Revisiting Sparse Rewards for Goal-Reaching Reinforcement Learning
Gautham Vasan, Yan Wang, Fahim Shahriar, James Bergstra, Martin Jagersand, A. Rupam Mahmood
RLC 2024
Paper •
Demo •
Code
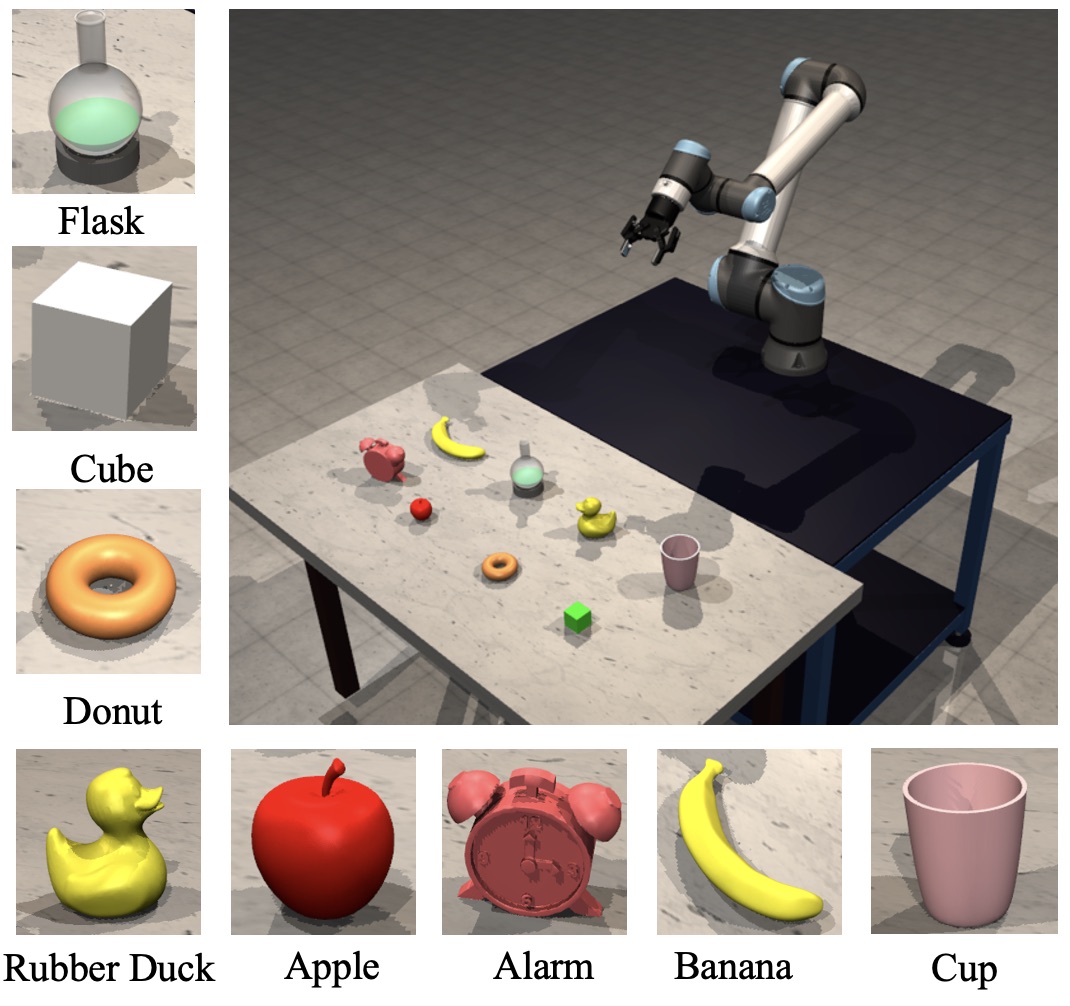
Versatile and Generalizable Manipulation via Goal-Conditioned Reinforcement Learning with Grounded Object Detection
Huiyi Wang, Fahim Shahriar, Alireza Azimi, Gautham Vasan, A. Rupam Mahmood, Colin Bellinger
CoRL MRM-D Workshop 2024
Paper

Autonomous Skill Acquisition for Robots Using Graduated Learning
Gautham Vasan
AAMAS Doctoral Consortium 2024
Paper
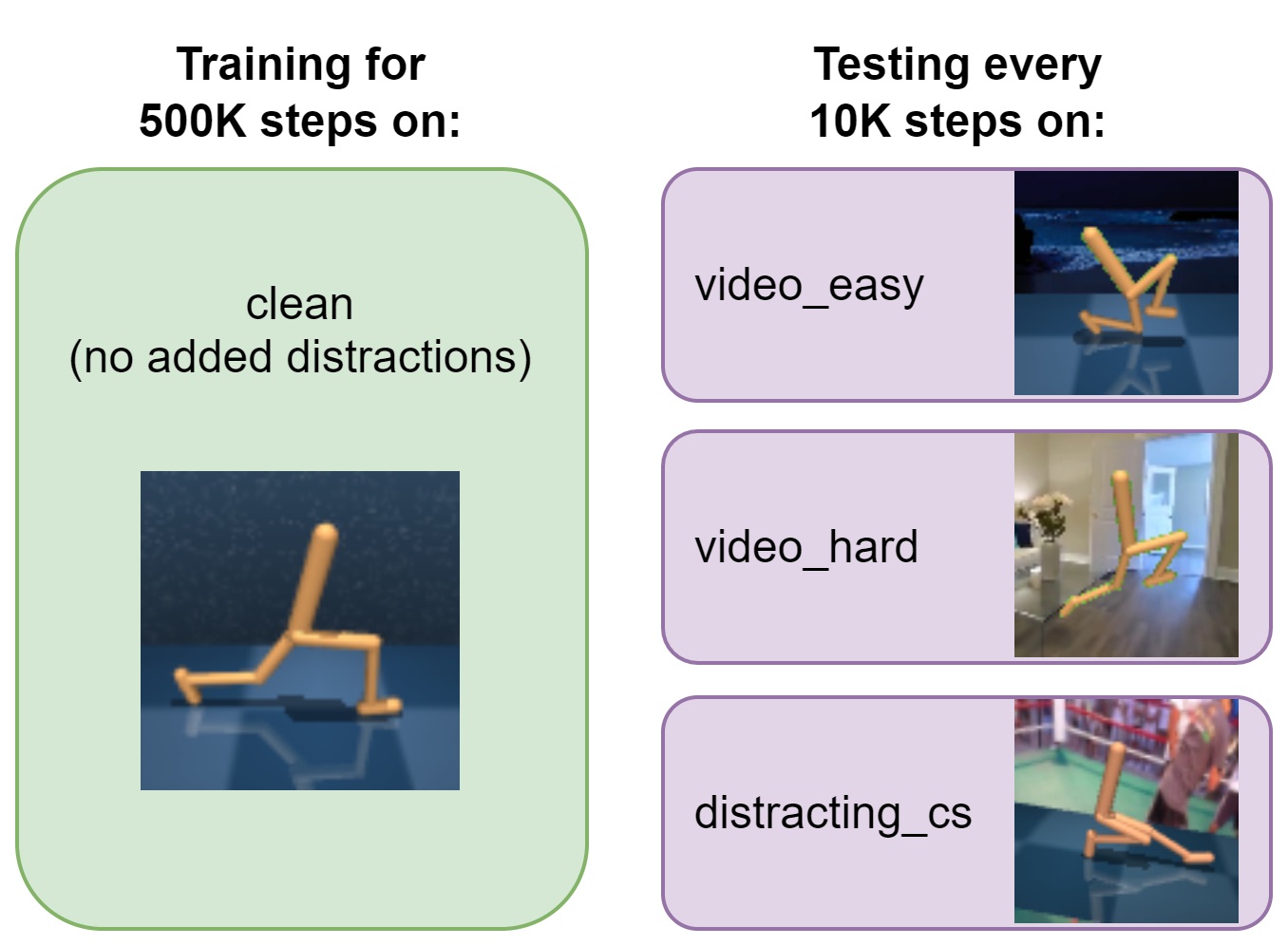
MaDi: Learning to Mask Distractions for Generalization in Visual Deep Reinforcement Learning
Bram Grooten, Tristan Tomilin, Gautham Vasan, Matthew E Taylor, A Rupam Mahmood, Meng Fang, Mykola Pechenizkiy, Decebal Constantin Mocanu
AAMAS 2024
Paper •
Video
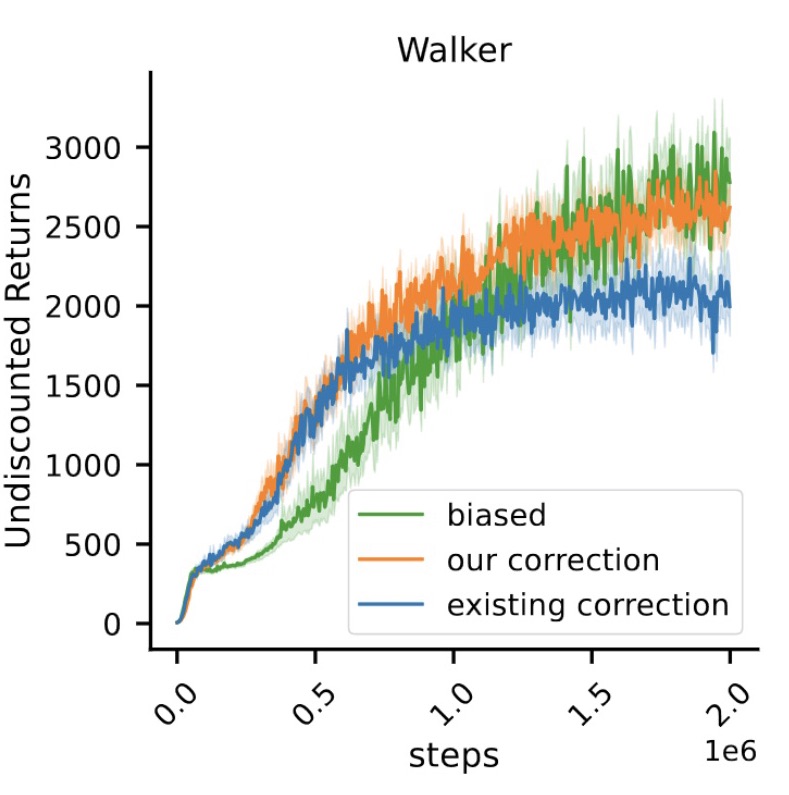
Correcting Discount-Factor Mismatch in On-Policy Policy Gradient Methods
Fengdi Che, Gautham Vasan, A. Rupam Mahmood
ICML 2023
Paper
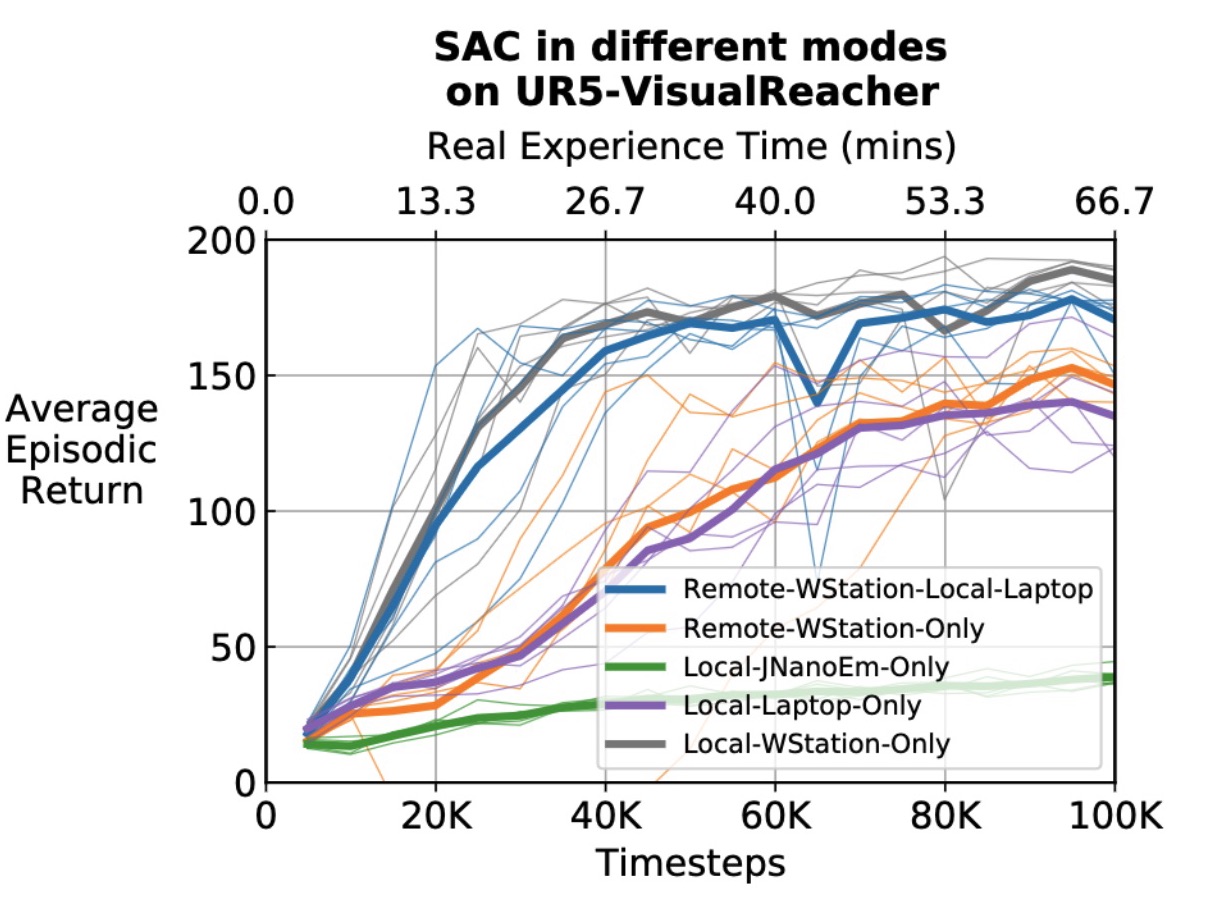
Real-Time Reinforcement Learning for Vision-Based Robotics Utilizing Local and Remote Computers
Yan Wang*, Gautham Vasan*, A. Rupam Mahmood
ICRA 2023
Paper •
Video
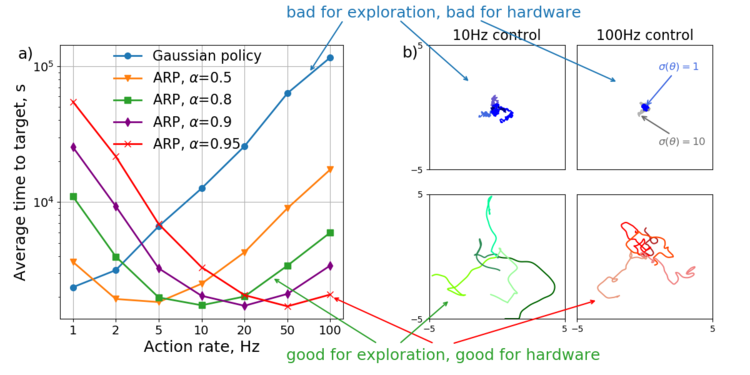
Autoregressive policies for continuous control deep reinforcement learning
Dmytro Korenkevych, A Rupam Mahmood, Gautham Vasan, James Bergstra
IJCAI 2019
Paper •
Post •
Video

Benchmarking reinforcement learning algorithms on real-world robots
A Rupam Mahmood, Dmytro Korenkevych, Gautham Vasan, William Ma, James Bergstra
CoRL 2018
Paper •
Post •
Video •
SenseAct

Context-Aware Learning from Demonstration: Using Camera Data to Support the Synergistic Control of a Multi-Joint Prosthetic Arm
Gautham Vasan, Patrick M Pilarski
BioRob 2018
Paper •
Poster

Learning from demonstration: Teaching a myoelectric prosthesis with an intact limb via reinforcement learning
Gautham Vasan, Patrick M Pilarski
ICORR 2017
Spotlight presentation at Rehabweek 2017.
Paper •
Video & Metadata

Mirrored Bilateral Training of a Myoelectric Prosthesis with a non-amputated arm via Actor-Critic Reinforcement Learning
Gautham Vasan, Patrick M Pilarski
RLDM 2017
Spotlight presentation (20min)
Poster •
Slides
Neurohex: A Deep Q-Learning Hex Agent
Kenny Young, Gautham Vasan, Ryan Hayward
Computer Games Workshop at IJCAI 2016
Paper

Autonomous Visual Tracking and Landing of a Quadrotor on a Moving Platform
Juhi Ajmera, PR Siddharthan, KM Ramaravind, Gautham Vasan, Naresh Balaji, V Sankaranarayanan
IEEE ICIIP 2015
Paper •
Video

A Control Strategy for an Autonomous Robotic Vacuum Cleaner for Solar Panels
Gautham Vasan, G Aravind, TSB Gowtham Kumar, R Naresh Balaji, G Saravana Ilango
IEEE Texas Instruments India Educators Conference 2014
Phase-I Winners and finalists (top 19 among 2000+ teams)
Paper •
Video •
Presentation
Deep Policy Gradient Methods Without Batch Updates, Target Networks, or Replay Buffers
Two Issues of Autonomous Robot Learning
Reward (Mis-)Specification in Reinforcement Learning
natChat: Neurotech in Artificial Intelligence (2023)
Professional Activities
- Workflow Chair for AAAI 2026
- Reviewer: ICML, RLC, Collas, ICLR, NeurIPS, BioRob, ICORR, ICDL, IROS
- Candidate selection for the CIFAR Deep Learning and Reinforcement Learning Summer School 2023 & 2024
- Mentoring: Six students at the University of Alberta (undergraduate and masters level) on robot learning research
Community Service
- Research volunteer with The Hospital for Sick Children (SickKids, 2019)
- Cerebral Palsy and Spasticity Trials: Worked with doctors on a study assessing functional gain in patients affected by stroke or spasticity using assistive robots.
Teaching Experience
- CMPUT 340: Introduction to Numerical Methods (Winter 2024)
- CMPUT 653: Real-Time Policy Learning (Fall 2023)
- CMPUT 365: An Introduction to Reinforcement Learning (Winter 2021, Winter 2022, Fall 2022)
- CMPUT 174: Introduction to the Foundations of Computation I (Fall 2015, Winter 2016, Fall 2020)