Moravec's paradox, Sim-to-Real Transfer & Robot Learning
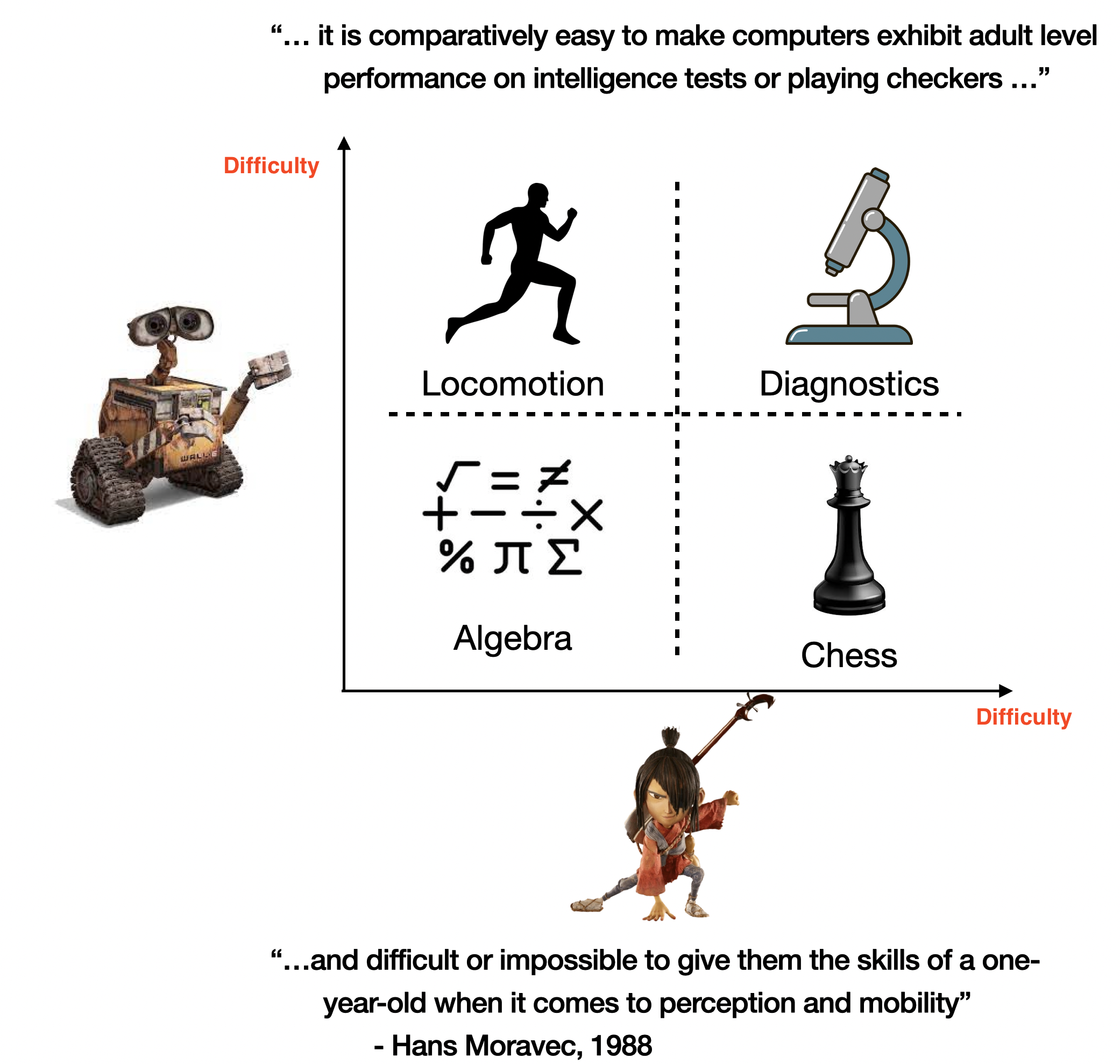
Moravec’s paradox
Early Artificial Intelligence (AI) researchers focused on tasks they found challenging, like games and activities requiring reasoning and planning. Unfortunately, they often overlooked the learning abilities observed in animals and one-year-olds. The deliberate process we call reasoning is effective only because its supported by a much more powerful, though usually unconscious, sensorimotor knowledge. We are exceptionally good in perceptual and motor learning, so good that we make the difficult look easy. For example, compared to robots, we might as well be Olympians in walking, running, recognizing objects, etc. Sensorimotor skills took millions of years to evolve, whereas abstract thinking is a relatively recent development. Keeping this in mind, Moravec wrote in 1988, “it is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility”.
There has been impressive headway in robotics research in recent years, largely driven by the strides made in machine learning. While the realm of AI research is currently heavily dominated by Large Language Model (LLM) researchers, there’s still a notable upswing in the enthusiasm for robotics research. In fact, works like Google’s RT-2 tantalizingly dangle the prospect of embodied AGI being just around the corner. For folks unfamiliar with the term, Artificial General Intelligence (AGI) refers to a hypothetical type of intelligent agent that, if realized, could learn to accomplish any intellectual task that human beings or animals can perform.
The integration of LLMs with robots is an exciting development mainly because it finally enables us to communicate with robots in a way that was once confined to the realm of science fiction. However, the current use of LLMs has been more focused on symbolic planning, requiring additional low-level controllers to handle the sensorimotor data. Despite the captivating demonstrations, it’s important to note that the foundational issues of Moravec’s paradox still persist…
A Line of Attack for Moravec’s Paradox?
In a recent TED talk, Prof. Pulkit Agrawal argues that while evolution required millions of years to endow us with locomotion priors/skills, but the development of logic & reasoning abilities occurred more swiftly, driven by the presence of underlying learning capabilities. His core argument is that simulation can compensate for millions of years of evolution, allowing us to acquire the necessary priors and inductive biases.
Simulators can provide a potentially infinite source of data for training robotic systems, which can be cost-prohibitive or impractical to obtain in the real world. Additionally, using simulations alleviates safety concerns associated with training and testing on real robots. Hence, there’s a LOT of interest in learning a control policy purely in simulation and deploying it on a robot. This line of research, popularly known as sim-to-real in robot learning, refers to the process of transferring a robotic control policy learned in a simulated environment to the real world.
The sim-to-real transfer process typically involves training a robotic control policy in a simulated environment and then adapting it to the real world. This adaptation is necessary due to the differences between simulation and reality, such as sensory noise, dynamics, and other environmental factors. Typically, there is a significant gap between simulated and real-world environments, which can lead to a degradation in the performance of policies when transferred to real robots.
Sim-to-Real: The Silver Bullet?
The basic idea behind the generative AI revolution is simple: Train a big neural network with a HUGE dataset from the internet, and then use it to do various structured tasks. For example, LLMs can answer questions, write code, create poetry, and generate realistic art. Despite these capabilities, we’re still waiting for robots from science fiction that can do everyday tasks like cleaning, folding laundry, and making breakfast.
Unfortunately, the successful generative AI approach, which involves big models trained on internet data, doesn’t seamlessly scale to robotics. Unlike text and images, the internet lacks abundant data for robotic interactions. Current state-of-the-art robot learning methods require data grounded in the robot’s sensorimotor experience, which needs to be slowly and painstakingly collected by researchers in labs for particular tasks. The lack of extensive data prevents robots from performing real-world tasks beyond the lab, such as making breakfast. Impressive results usually stay confined to a single lab, a single robot, and often involve only a few hard-coded behaviors.
Drawing inspiration from Moravec’s paradox, the success of generative AI, and Prof. Rich Sutton’s post on The Bitter Lesson, the robot learning community’s biggest takeaway so far is that we do not have enough data.
While there is some validity to criticisms, like The Better Lesson by Dr. Rodney Brooks, we can all still agree that we’re going to need a lot of data for robot learning.
The real question is, where does that data come from? Currently, I see three data sources, and it’s worth noting that they do not have to be independent of each other:
- Large-scale impressive efforts, like Open X-Embodiment, where a substantial group of researchers collaborated to collect robot learning data for public use.
- Massive open world simulators which can be used for Sim-to-Real Transfer for Robot Learning.
- Real-Time Learning on Real World Robots!
- This may be painstakingly slow and tedious. But this is also a necessary feature if we envision truly intelligent machines that can learn and adapt on the fly as they interact with the world.
For points 1 & 3, the downside is the amount of human involvement required. It is incredibly challenging to autonomously collect robot learning data, which can indeed pose a significant barrier. Now let’s talk about why most roboticists are currently paying a lot of attention to sim-to-real learning methods.
✅ The Appeal of Sim-to-Real
- Infinite data: Simulators offer a potentially infinite source of training data for robots, as acquiring large amounts of real-world robot data is often prohibitively expensive or impractical.
- The pain of working with hardware: Researchers often favor simulators in their work due to the convenience of avoiding hardware-related challenges. Simulated environments provide a controlled and reproducible setting, eliminating the need to contend with physical hardware issues, allowing researchers to focus more on algorithmic and learning aspects.
- I love this sentiment shared by Prof. Patrick Pilarski, my M.Sc advisor: “Robots break your heart. They break down at the worst possible moment - right before a demo or a deadline.”
- Differentiable physics: There are simulators with differentiable physics. This fits nicely with certain approaches, especially with trajectory optimization in classical robotics. This also helps with estimating gradients of the reward or gradient of a value function with respect to the state in RL.
- In the real world, we do not have differentiable physics.
- Domain randomization is a crucial step in all sim-to-real approaches. This has more to do with robustness to changes rather than online adaptation. With sim-to-real, we want to expose the agent to as many scenarios as possible in the simulator before deployment. OpenAI’s solving a Rubik’s cube with a robot hand demo is a fantastic showcase of this approach.
- The focus is not really on learning on the fly, but rather being robust to perturbations.
- World models: The simulator is a pseudo-reinforcement-learning-model which can help learn a value function better (assuming its a good simulator)
- This, however is not the same as learning a world model, rather trying to replicate the world to solve a very specific real-world task
While sim-to-real has its merits, I believe it may not be sufficient as there are key limitations that still need to be addressed.
❌ Limitations of Sim-to-Real
- Sim-to-Real Gap: We are limited in our ability to replicate the real world. Our simulators, for example, cannot faithfully replicate friction or contact dynamics. Small errors in simulations can compound and significantly degrade the performance of policies learned in simulation when applied to real robots.
- Accuracy of simulators: While techniques such as domain randomization, and domain adaptation can help mitigate these limitations, they may not be sufficient for tasks requiring detailed simulations, especially in domains like agricultural robotics.
- Cost of building simulators: Another concern for me is that no one discusses the computational expenses associated with simulators. High-fidelity simulators can be extremely costly to both develop and maintain.
To answer the question posed at the start of this section - No, but… I believe we can benefit immensely by incorporating simulators into our learning methods when appropriate. The issue is more nuanced than a simple yes or no :)
Closing Thoughts
In the research community, I’ve noticed the widespread adoption of the term ‘Out-of-distribution’ (OOD). In robot learning, it denotes the challenge of handling data that deviates from the training data. Personally, I loathe this term. By the very nature of the learning problem, we acknowledge that preparing robots for all conceivable scenarios in advance is impossible. If we could predict every scenario, the need for learning methods would be obsolete! OOD essentially makes a case for integrating the test set into the training set, a notion that was once considered blasphemous in machine learning before the era of LLMs.
Our current robot learning playbook seems to involve throwing a vast amount of data at our limited, not-so-great algorithms in simulation via domain randomization, with the hope that it encompasses all potential deployment scenarios. In addition, there’s also a huge aversion to learning directly on the robot for an extended period of time. In my opinion, this strategy is doomed to fail because we possibly cannot, and will not be able to, model the entire world with a high degree of precision and accuracy.
I do believe that pre-training models using sim-to-real can serve as a good starting point. It can be a fantastic litmus test to rule out ineffective approaches. But clearly, we cannot expose our robots to all possible scenarios via training in simulation. The general-purpose robots we dream of must also have the ability to learn on-the-fly as they interact with the physical world in real-time. I believe we are making significant strides in refining sim-to-real methods. But there has been relatively little interest in studying the real-time adaptation and fine-tuning abilities of these learning systems in the real world. While success in our controlled lab settings is promising, it’s imperative that we stress-test our ideas by deploying them in unstructured real-world scenarios. And it might surprise us to discover that there’s an entirely new set of challenges awaiting us in real-world deployment, issues that are often overlooked or not encountered within controlled lab settings.
I’m curious about the insights my peers glean from the current state of research. Personally, my focus will be on developing continual learning systems capable of real-time adaptation for robots. However, I’m eager to see if the community proposes alternative, ingenious solutions to address the challenges of our era. All in all, it’s an exciting time to be involved in robot learning research. Let’s see what we end up building in the near future!
Addendum
- I came across another great post in a similar vein: Will Scaling Solve Robotics?: Perspectives From Corl 2023. Definitely worth a read!
- This article is pretty neat too: Kaelbling, L. P. (2020). The foundation of efficient robot learning. Science, 369(6506), 915-916.
Acknowledgements
Thanks to Prof. Rupam Mahmood and Shivam Garg for several thoughtful discussions on this topic that have greatly shaped my views.